

 Browse All 30K+ Problems
Browse All 30K+ Problems
Some Example Problems
Browse by country & competition
Jump straight into a national Olympiad or international competition.
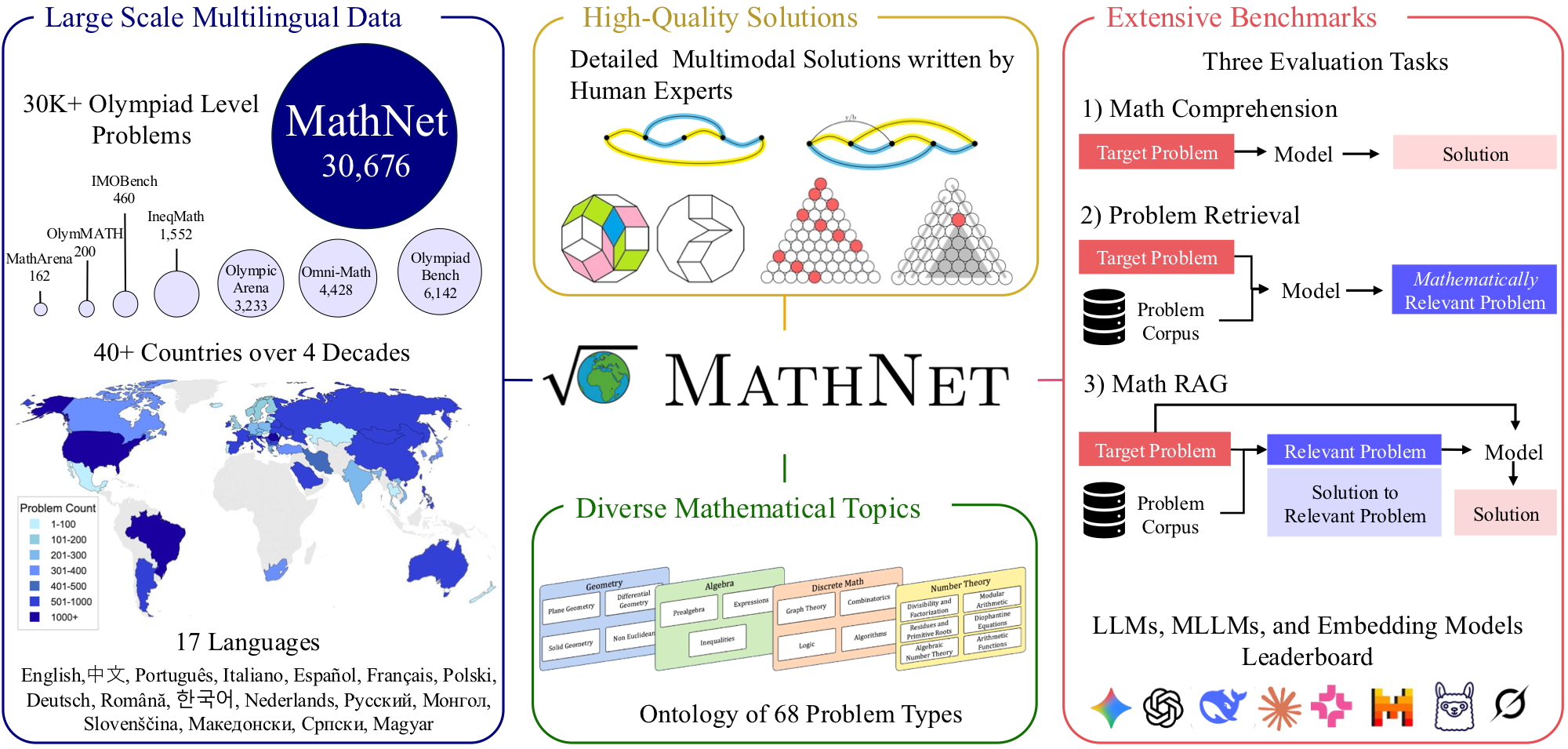
Mathematical problem solving remains a challenging test of reasoning for large language and multimodal models, yet existing benchmarks are limited in size, language coverage, and task diversity. We introduce MathNet, a high-quality, large-scale, multimodal, and multilingual dataset of Olympiad-level math problems together with a benchmark for evaluating mathematical reasoning in generative models and mathematical retrieval in embedding-based systems.
MathNet spans 47 countries, 17 languages, and two decades of competitions, comprising 30,676 expert-authored problems with solutions across diverse domains. In addition to the core dataset, we construct a retrieval benchmark consisting of mathematically equivalent and structurally similar problem pairs curated by human experts.
MathNet supports three tasks: (i) Problem Solving, (ii) Math-Aware Retrieval, and (iii) Retrieval-Augmented Problem Solving. Experimental results show that even state-of-the-art reasoning models (78.4% for Gemini-3.1-Pro and 69.3% for GPT-5) remain challenged, while embedding models struggle to retrieve equivalent problems. We further show that RAG performance is highly sensitive to retrieval quality; for example, DeepSeek-V3.2-Speciale achieves gains of up to 12%, obtaining the highest scores on the benchmark. MathNet provides the largest high-quality Olympiad dataset together with the first benchmark for evaluating mathematical problem retrieval, and we publicly release both the dataset and benchmark.
MathNet supports three tasks. The first tests whether models can solve Olympiad problems outright. The second tests whether embedding models can retrieve mathematically equivalent problems from a large pool. The third combines both: does giving a model a similar problem as context actually help?
MathNet covers 47 countries and 17 languages, with problems spanning two decades of competition math. The solutions are long (considerably longer than those in existing benchmarks), which is part of what makes evaluation harder.
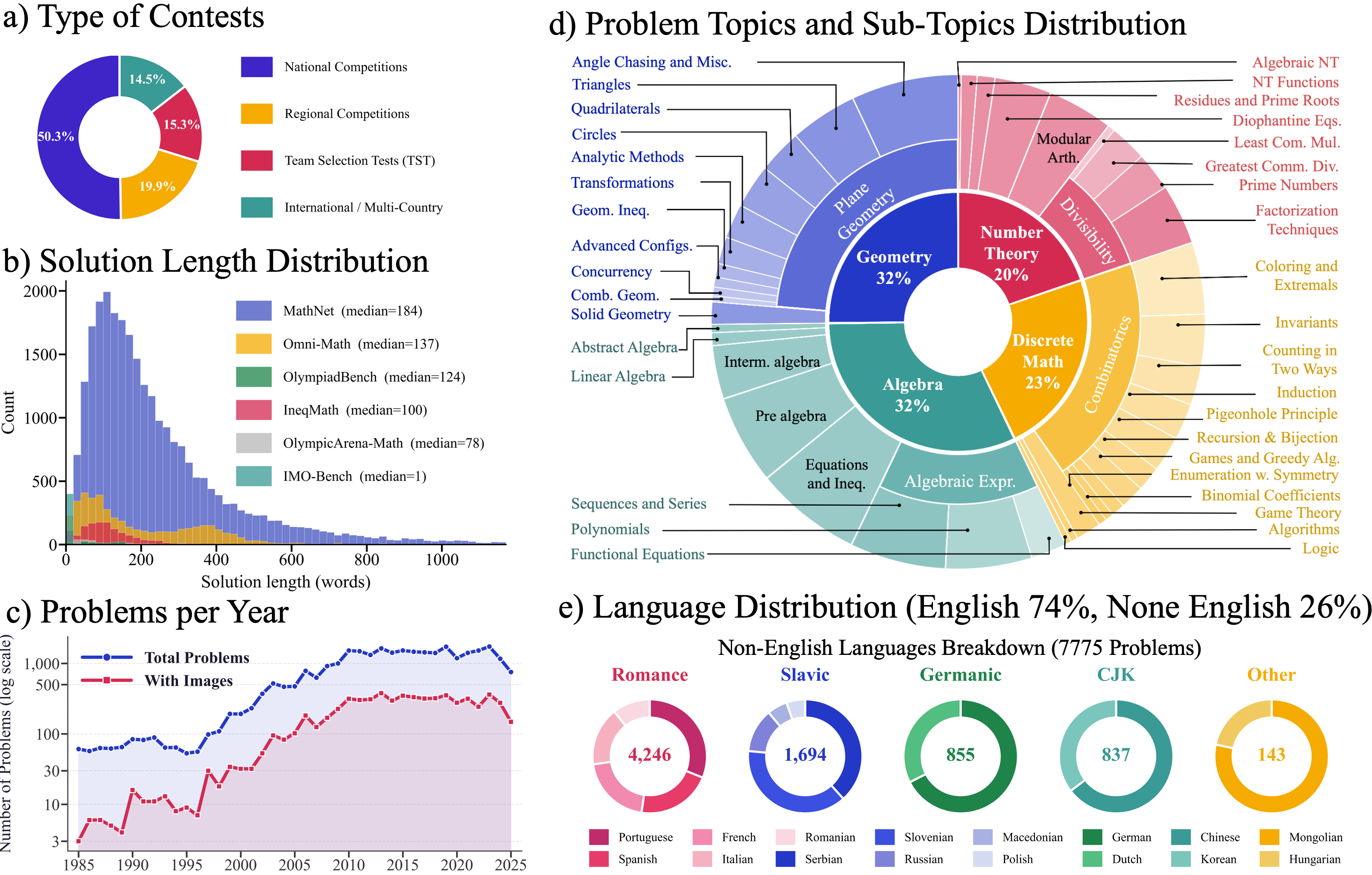
MathNet dataset statistics. (a) Contest type distribution. (b) Solution length vs. existing benchmarks — MathNet solutions are much longer. (c) Problems per year. (d) Topic and sub-topic distribution. (e) Language distribution: 74% English, 26% non-English across 17 languages.
Each problem starts as a scanned competition booklet. We run OCR, split the text into problem–solution pairs, normalize the formatting, and have human experts verify the output before anything enters the dataset.
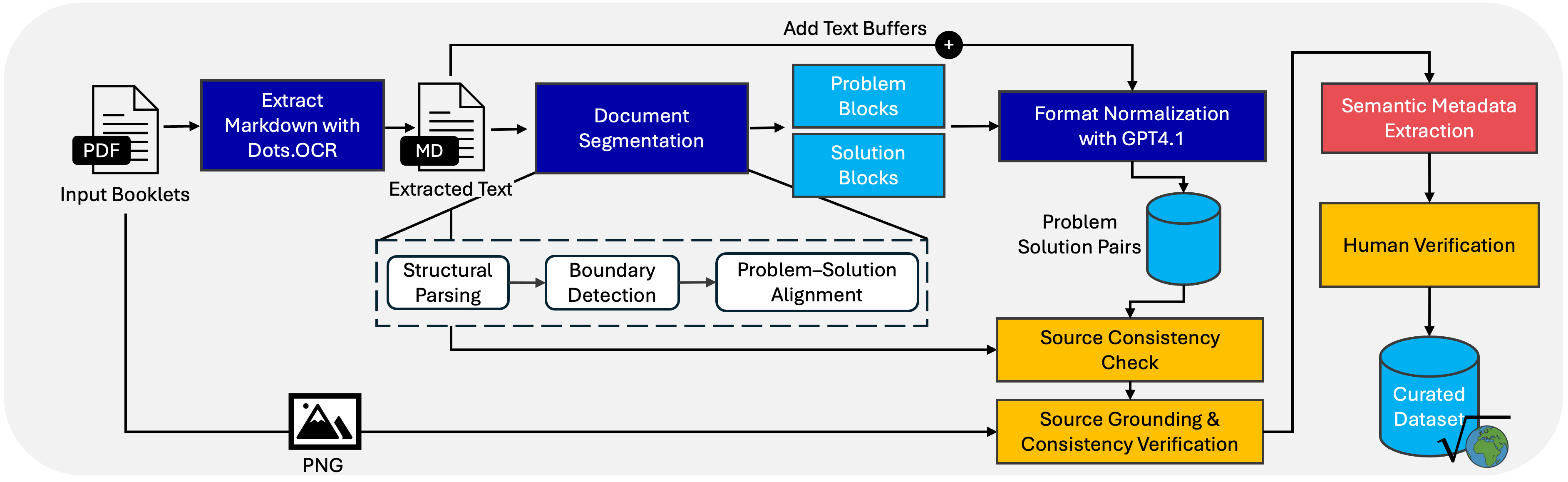
Data extraction and curation pipeline. Competition PDFs are converted to markdown via OCR, split into problem–solution blocks, normalized with GPT-4.1, and verified by human experts.
The top solving model hits 78.4%, which's very strong; however, retrieval is the bigger gap: Recall@1 stays below 5% for every model we tested. Expert-retrieved context helps solving accuracy, but only when the retrieval is actually good.
MathNet-Solve-Test
Problem Solving on MathNet-Solve-Test (6,400 problems).
Takeaway: LMMs with reasoning are clearly strongest overall, but even the top model remains well below perfect performance.
MathNet-Retrieve
Math-Aware Retrieval on MathNet-Retrieve (10,000 anchor problems).
Takeaway: Recall@1 stays very low even for the best models, while Recall@5 is much stronger, showing that mathematically equivalent retrieval is still unreliable at shallow depths.
MathNet-RAG
Retrieval-Augmented Problem Solving on MathNet-RAG (35 problems).
Takeaway: Expert retrieval most often gives the strongest gains, but improvements remain model-dependent and grading-dependent.
If you use MathNet in your work, please cite the paper.
@inproceedings{alshammari2026mathnet,
title = {MathNet: A Global Multimodal Benchmark for Mathematical
Reasoning and Retrieval},
author = {Alshammari, Shaden and Wen, Kevin and Zainal, Abrar and
Hamilton, Mark and Safaei, Navid and Albarakati, Sultan and
Freeman, William T. and Torralba, Antonio},
booktitle = {International Conference on Learning Representations},
year = {2026},
url = {https://mathnet.mit.edu}
}
For questions about the dataset, benchmark, or paper, reach out to shaden@mit.edu.